Shared Modular Policies for Agent-Agnostic Control
Reinforcement learning is typically concerned with learning control policies tailored to a particular agent. We investigate whether there exists a single global policy that can generalize to control a wide variety of agent morphologies -- ones in which even dimensionality of state and action spaces changes. We propose to express this global policy as a collection of identical modular neural networks, dubbed as Shared Modular Policies (SMP), that correspond to each of the agent's actuators. Every module is only responsible for controlling its corresponding actuator and receives information from only its local sensors. In addition, messages are passed between modules, propagating information between distant modules. We show that a single modular policy can successfully generate locomotion behaviors for several planar agents with different skeletal structures such as monopod hoppers, quadrupeds, bipeds, and generalize to variants not seen during training -- a process that would normally require training and manual hyperparameter tuning for each morphology. We observe that a wide variety of drastically diverse locomotion styles across morphologies as well as centralized coordination emerges via message passing between decentralized modules purely from the reinforcement learning objective.
Shared Modular Policies
This work takes a step beyond the laborious training process of the conventional single-agent RL policy by tackling the possibility of learning general-purpose controllers for diverse robotic systems. Our approach leverages the compositional graph neural networks and trains a single policy for a wide variety of agents which can then generalize to unseen agent shapes at test-time without any further training.
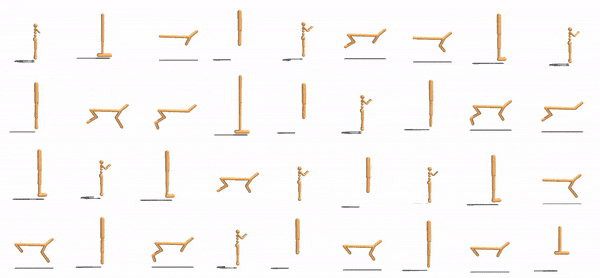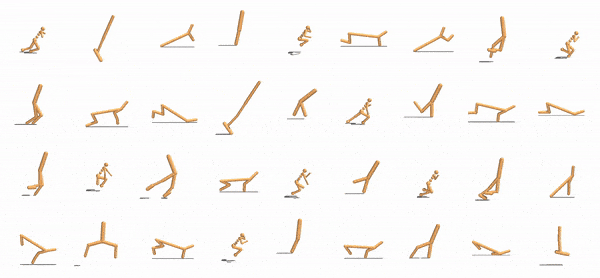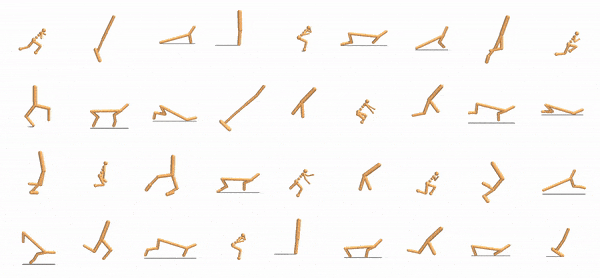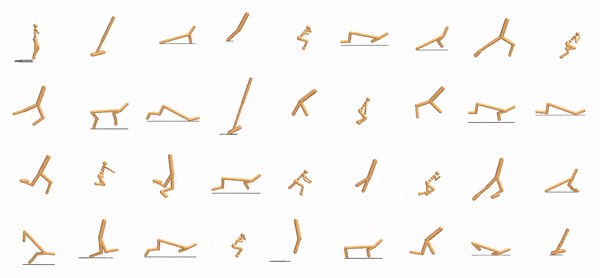 |
Overview of the Algorithm
Our method expresses agents as collections of modular components that use a shared control policy. Multiple agent controllers (left) are trained simultaneously with locally communicating modules with shared parameters (center). These modules learn to pass messages to local neighbors (right).
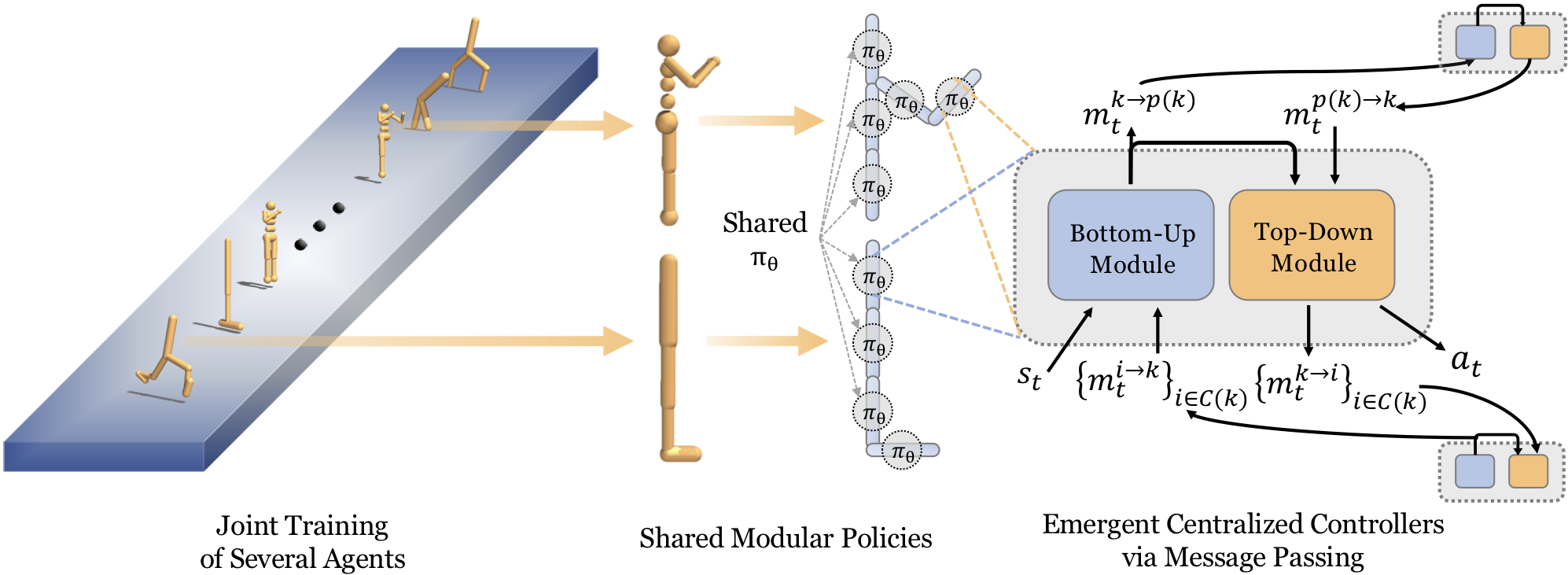 |
Source Code
We have released our implementation in PyTorch on the github page. Try our code!
[GitHub]
Related Work
Deepak Pathak*, Chris Lu*, Trevor Darrell, Phillip Isola, Alexei A. Efros. Learning to Control Self-Assembling Morphologies: A Study of Generalization via Modularity. NeurIPS 2019. [website] [paper]
Paper and Bibtex

|
Wenlong Huang, Igor Mordatch, Deepak Pathak. One Policy to Control Them All: Shared Modular Policies for Agent-Agnostic Control. ICML 2020. [Bibtex] |
|
@inproceedings{huang2020smp,
Author = {Huang, Wenlong and
Mordatch, Igor and Pathak, Deepak},
Title = {One Policy to Control Them All:
Shared Modular Policies for Agent-Agnostic Control},
Booktitle = {ICML},
Year = {2020}
}
|
Acknowledgements
We would like to thank Alyosha Efros, Yann LeCun, Jitendra Malik, Pieter Abbeel, Yuandong Tian, Hang Gao and the members of BAIR community for fruitful discussions. This work was supported in part by Google faculty research award.