|
I am a Ph.D. candidate in Computer Science at Stanford, advised by Fei-Fei Li as part of the Stanford Vision and Learning Lab (SVL). Currently, I am a visiting student at MIT CSAIL, working with Leslie Kaelbling and Tomás Lozano-Pérez.
I received my B.A. in Computer Science from UC Berkeley (2018 - 2021), advised by Deepak Pathak, Igor Mordatch, and Pieter Abbeel.
I have spent time at Seattle Robotics Lab at NVIDIA (2024) and Robotics team at Google Brain (2022).
Previously, I also worked with Zhuowen Tu at UC San Diego (2018). Email (wenlongh [AT] stanford.edu) / Google Scholar / Twitter / GitHub |

|
|
|
The goal of my research is to endow robots with broad generalization capabilities for open-world manipulation tasks, especially in household environments. Towards this goal, I am interested in 1) developing structured representations that leverage foundation models and Internet-scale data, and 2) developing algorithms that exhibit broadly generalizable behaviors. |
|
Keypoint Constraints for Robotic Manipulation Wenlong Huang, Chen Wang*, Yunzhu Li*, Ruohan Zhang, Li Fei-Fei The Conference on Robot Learning (CoRL), 2024 Best Paper Award at the 2024 CoRL LEAP Workshop Project Page / Paper / Code / Video / Summary Large vision models and vision-language models can generate keypoint-based constraints, which can be optimized to achieve multi-stage, in-the-wild, bimanual, and reactive behaviors, without task-specific training or environment models. |
|
|
for Generalization in Robotic Manipulation Yihe Tang, Wenlong Huang*, Yingke Wang, Chengshu Li, Roy Yuan, Ruohan Zhang, Jiajun Wu, Li Fei-Fei International Conference on Robotics and Automation (ICRA), 2025 Best Paper Award Finalist Project Page / Paper / Code / Summary Fine-grained task-conditioned visual affordance can be distilled from off-the-shelf foundation models, enabling diverse generalization properties in downstream policy learning. |
|
|
with VLM-Generated Iterative Keypoint Rewards Shivansh Patel*, Xinchen Yin*, Wenlong Huang, Shubham Garg, Hooshang Nayyeri, Li Fei-Fei, Svetlana Lazebnik, Yunzhu Li International Conference on Robotics and Automation (ICRA), 2025 Project Page / Paper / Code / Video / Summary Vision-Language Models can serve as human proxies specify diverse task objectives by writing keypoint-based reward functions, where they can be autonomously and iteratively refined based on environment feedback. |
|
|
for Robotic Manipulation with Language Models Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, Li Fei-Fei The Conference on Robot Learning (CoRL), 2023 Oral Presentation Project Page / Paper / Code / Video / Summary Large language models and visual-language models can be used to directly label affordances and constraints in the 3D perceptual space. Combined with motion planning, this enables robots to perform diverse everyday manipulation tasks in a zero-shot manner. |
|
|
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence International Conference on Machine Learning (ICML), 2023. Project Page / Paper / Google AI Blog / Summary Language models can digest real-world sensor modalities (e.g., images) to be embodied in the physical world. The largest 562B model is a generalist agent across language, vision, and task planning. |
|
|
Guiding Text Generation with Grounded Models for Robot Control Wenlong Huang, Fei Xia, Dhruv Shah, Danny Driess, Andy Zeng, Yao Lu, Pete Florence, Igor Mordatch, Sergey Levine, Karol Hausman, Brian Ichter Conference on Neural Information Processing Systems (NeurIPS), 2023 Project Page / Paper / Video / Summary Large language models can be grounded in embodied environments by using continuous probabilities to guide their token decoding, where the guidance is provided by a set of grounded models, such as affordance, safety, and preference functions. |
|
|
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng International Conference on Robotics and Automation (ICRA), 2023 Outstanding Robot Learning Paper Award Project Page / Paper / Code / Video / Google AI Blog / TechCrunch / Summary Using hierarchical code generation, language models can write robot policy code that exhibits spatial-geometric reasoning given abstract natural language instructions. |
|
|
Embodied Reasoning through Planning with Language Models Wenlong Huang*, Fei Xia*, Ted Xiao*, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, Brian Ichter The Conference on Robot Learning (CoRL), 2022 Project Page / Paper / Video / Two Minute Papers / Summary Provided with textual embodied feedback, language models can articulate a grounded "thought process", solving challenging long-horizon robotic tasks, even under disturbances. |
|

|
Extracting Actionable Knowledge for Embodied Agents Wenlong Huang, Pieter Abbeel, Deepak Pathak*, Igor Mordatch* International Conference on Machine Learning (ICML), 2022. Project Page / Paper / Code / Video / Summary Large language models (e.g. GPT-3, Codex) contain rich actionable knowledge that can be used to plan actions for embodied agents, even without additional training. |

|
via Geometry-Aware Multi-Task Learning Wenlong Huang, Igor Mordatch, Pieter Abbeel, Deepak Pathak arXiv, 2021 Project Page / Paper / Code / Summary With appropriate object representation, a multi-task RL policy can control an anthropomorphic hand to manipulate 100+ diverse objects and achieve SOTA performance on unseen ones. |
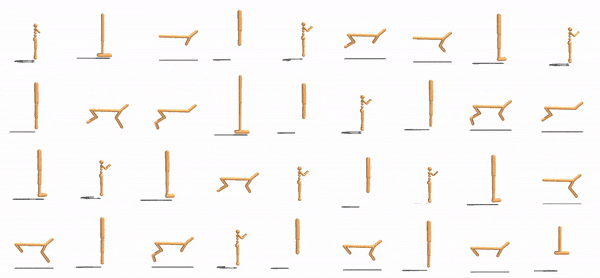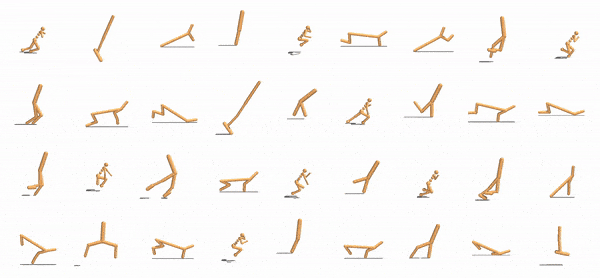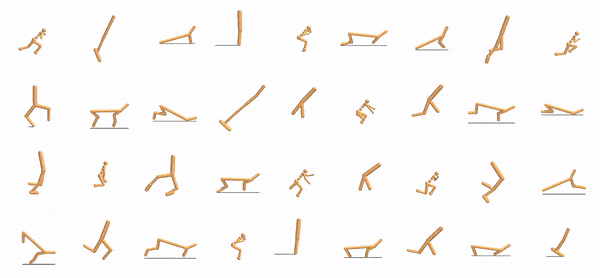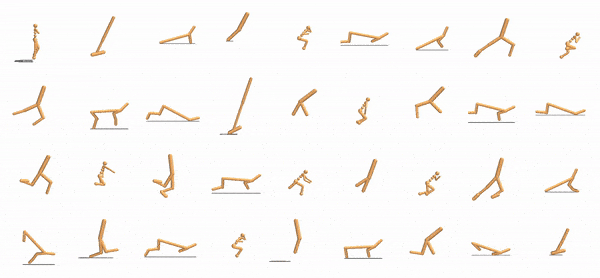
|
Shared Modular Policies for Agent-Agnostic Control Wenlong Huang, Igor Mordatch, Deepak Pathak International Conference on Machine Learning (ICML), 2020. Project Page / Paper / Code / Video / Oral Talk / Summary Expressing robots as collections of modular components that share a control policy can lead to zero-shot generalization across diverse unseen robot morphologies. |

|
Wenlong Huang*, Brian Lai*, Weijian Xu, Zhuowen Tu Association for the Advancement of Artificial Intelligence (AAAI), 2019. Paper Built upon Generative via Discriminative Learning and Introspective Learning frameworks, a single neural network can simultaneously perform classification and generation of 3D volumetric shapes. |
|
|